Article
Avro to Hbase using Apache Beam
這邊使用 python sdk 串 Google DataFlow,下面介紹相關概念
概念介紹
Apache Beam
前身是 Google DataFlow,是一套用來執行batch/streaming data-parallel processing 的 pipeline,在 Embarrassingly Parallel (資料可以良好的被拆分成多個組合)的資料處理任務很好用。
目前提供分散式的後端支援:
- Apache Apex
- Apache Flink
- Apache Samza
- Apache Spark
- Google Cloud Dataflow
- Hazelcast Jet
以及三種 sdk:Java、Python、GO
Programing concept
- Pipeline:單一 task 的稱呼,包含 reading => transforming => writing 的一系列動作
- PCollection:每個 job 處理的 data set的稱呼,有
bounded(batch) 跟unbounded(streaming) 的分別 - PTransform: 表示 pipeline 中一個 job 的處理流程(步驟),包含1
n個 PCollection 作為 input,0n 個 PCollection 作為 output
一個最單純的 pipeline 用圖形表示如下

- Transforms 有幾種類型如下
| name | describe |
|---|---|
| ParDo | Use for general parallel processing, 需搭配DoFn使用 |
| GroupByKey | Processing collections of key-value pairs |
| CoGroupByKey | Join two or more key-value PCollections that have same key type, 用再多來源在描述同一件事情時 |
| Combine | Combining collections of elements or values in your data, 使用時必須要提供 combine function |
| Flatten | Merges multiple PCollection objects into a single logical PCollection, 用在相同 data type 的 PCollections |
| Partition | Splits a single PCollection into a fixed number of smaller collections, 用在相同 data type 的 PCollections |
- Basic requirements
- Your function object must be serializable.
- Your function object must be thread-compatible, and be aware that the Beam SDKs are not thread-safe.
這邊簡單寫到這,官方文件寫的蠻好懂的,有空可以去細讀
Hbase
一個開源版的分散式資料庫,理論基礎為 BigTable 又可稱為開源版的 BigTable,在 Hadoop ecosystem 裡面擔任 data storage 的角色,使用 HDFS 實現 fault tolerance
- 與 RDBMS 的比較
| HBase | RDBMS |
|---|---|
| HBase is schema-less, it doesn’t have the concept of fixed columns schema; defines only column families. | An RDBMS is governed by its schema, which describes the whole structure of tables. |
| It is built for wide tables. HBase is horizontally scalable. | It is thin and built for small tables. Hard to scale. |
| No transactions are there in HBase. | RDBMS is transactional. |
| It has de-normalized data. | It will have normalized data. |
| It is good for semi-structured as well as structured data. | It is good for structured data. |
- 與 HDFS 的關係
| HDFS | HBase |
|---|---|
| HDFS is a distributed file system suitable for storing large files. | HBase is a database built on top of the HDFS. |
| HDFS does not support fast individual record lookups. | HBase provides fast lookups for larger tables. |
| It provides high latency batch processing; no concept of batch processing. | It provides low latency access to single rows from billions of records (Random access). |
| It provides only sequential access of data. | HBase internally uses Hash tables and provides random access, and it stores the data in indexed HDFS files for faster lookups. |
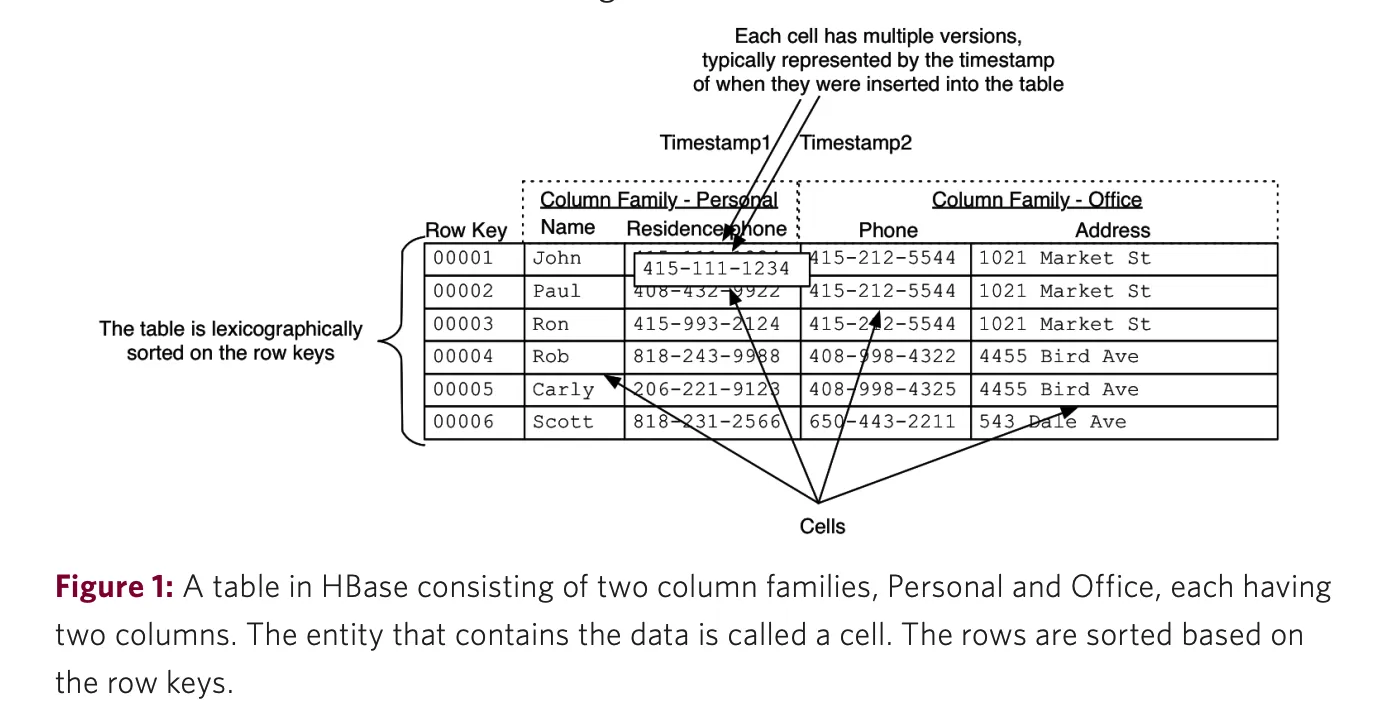
Data model terminology
| term | description |
|---|---|
| table | 由多個 row 組成 |
| row | 由row key + column family 組成,依照字母排序,設計row key應盡量讓相似的 pattern 放一起 |
| column | 由 column qualifier 與 column family 組成, 使用 colon character 做定界符號 |
| column family | 物理上將 column 分群,因此在create table時須先設定且不易修改,每個 row 都有相同的 column family,但不一定每個 column 都會有資料(sparse) |
| column qualifier | 提供 column family index 的基礎,可以後設但不能輕易修改 |
| cell | 一個資料源的最小單位(atom),預設保留 3 個版本,column family + column qualifier + row + value + timestamp |
| timestamp | 作為版本識別使用,不指定的話使用當下時間,讀取時預設抓取最新版本 |
以圖片呈現他們的關係如下
Running mode
- standalone
- default mode
- run on local filesystem
- No HDFS
- HMaster daemon only
- Never use on production
- Single node Single process
- pseudo distributed
- Use HDFS or local filesystem
- Single node Multi process
- Recommend to use on production
- fully distributed
- Use only HDFS
- cluster
- Best way to use on production
安裝可參考我之前的記錄
Avro
由 hadoop 之父創造的一種檔案格式,由於是 language-neutral 因此可以被多種語言處理,廣泛被用於 hadoop 體系,是一種效率很高的檔案格式